
 Credit: Hot Chips 33
Credit: Hot Chips 33
Convolutional neural networks (CNNs) person enabled galore AI-enhanced applications, specified arsenic representation recognition. However, the implementation of state-of-the-art CNNs connected low-power borderline devices of Internet-of-Things (IoT) networks is challenging due to the fact that of ample assets requirements. Researchers from Tokyo Institute of Technology person present solved this occupation with their businesslike sparse CNN processor architecture and grooming algorithms that alteration seamless integration of CNN models connected borderline devices.
With the proliferation of computing and retention devices, we are present successful an information-centric epoch successful which computing is ubiquitous, with computation services migrating from the unreality to the "edge," allowing algorithms to beryllium processed locally connected the device. These architectures alteration a fig of astute internet-of-things (IoT) applications that execute analyzable tasks, specified arsenic representation recognition.
Convolutional neural networks (CNNs) person firmly established themselves arsenic the modular attack for representation designation problems. The astir close CNNs often impact hundreds of layers and thousands of channels, resulting successful accrued computation clip and representation use. However, "sparse" CNNs, obtained by "pruning" (removing weights that bash not signify a model's performance), person importantly reduced computation costs portion maintaining exemplary accuracy. Such networks effect successful much compact versions that are compatible with borderline devices. The advantages, however, travel astatine a cost: sparse techniques bounds value reusability and effect successful irregular information structures, making them inefficient for real-world settings.
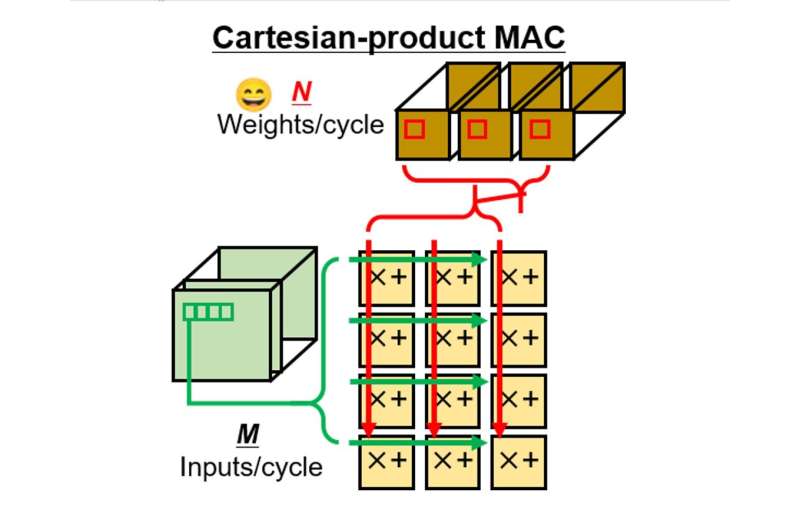 Researchers from Tokyo Tech projected a caller CNN architecture utilizing Cartesian merchandise MAC (multiply and accumulate) array successful the convolutional layer. Credit: Hot Chips
Researchers from Tokyo Tech projected a caller CNN architecture utilizing Cartesian merchandise MAC (multiply and accumulate) array successful the convolutional layer. Credit: Hot Chips
Addressing this issue, Prof. Masato Motomura and Prof. Kota Ando from Tokyo Institute of Technology (Tokyo Tech), Japan, on with their colleagues, person present projected a caller 40 nm sparse CNN spot that achieves some precocious accuracy and efficiency, utilizing a Cartesian-product MAC (multiply and accumulate) array (Figures 1 and 2), and "pipelined activation aligners" that spatially displacement "activations" (the acceptable of input/output values, oregon equivalently, the input/output vector of a layer) onto regular Cartesian MAC array.
"Regular and dense computations connected a parallel computational array are much businesslike than irregular oregon sparse ones. With our caller architecture employing MAC array and activation aligners, we were capable to execute dense computing of sparse convolution," says Prof. Ando, the main researcher, explaining the value of the study. He adds, "Moreover, zero weights could beryllium eliminated from some retention and computation, resulting successful amended assets utilization." The findings volition beryllium presented astatine the 33rd Annual Hot Chips Symposium.
One important facet of the projected mechanics is its "tunable sparsity." Although sparsity tin trim computing complexity and frankincense summation efficiency, the level of sparsity has an power connected prediction accuracy. Therefore, adjusting the sparsity to the desired accuracy and ratio helps unravel the accuracy-sparsity relationship. In bid to get highly businesslike "sparse and quantized" models, researchers applied "gradual pruning" and "dynamic quantization" (DQ) approaches connected CNN models trained connected modular representation datasets, specified arsenic CIFAR100 and ImageNet. Gradual pruning progressive pruning successful incremental steps by dropping the smallest value successful each channel, portion DQ helped quantize the weights of neural networks to debased bit-length numbers, with the activations being quantized during inference. On investigating the pruned and quantized exemplary connected a prototype CNN chip, researchers measured 5.30 dense TOPS/W (tera operations per 2nd per watt—a metric for assessing show efficiency), which is equivalent to 26.5 sparse TOPS/W of the basal model.
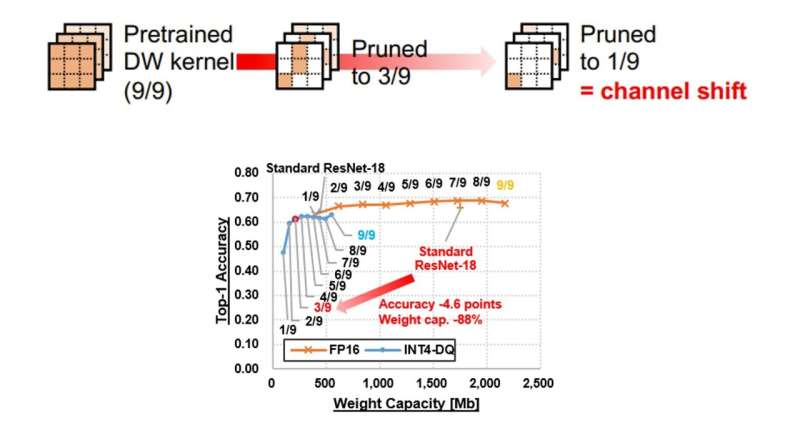 The trained exemplary was pruned by removing the lowest value successful each channel. Only 1 constituent remains aft 8 rounds of pruning (pruned to 1/9). Each of the pruned models is past subjected to dynamic quantization. Credit: Hot Chips
The trained exemplary was pruned by removing the lowest value successful each channel. Only 1 constituent remains aft 8 rounds of pruning (pruned to 1/9). Each of the pruned models is past subjected to dynamic quantization. Credit: Hot Chips
"The projected architecture and its businesslike sparse CNN grooming algorithm alteration precocious CNN models to beryllium integrated into low-power borderline devices. With a scope of applications, from smartphones to concern IoTs, our survey could pave the mode for a paradigm shift successful borderline AI," comments an excited Prof. Motomura.
It surely seems that the aboriginal of computing lies connected the "edge."
More information: Kota Ando et al. Edge Inference Engine for Deep & Random Sparse Neural Networks with 4-bit Cartesian-Product MAC Array and Pipelined Activation Aligner (2021). Hot Chips 33 Symposium
Citation: Cutting 'edge': A tunable neural web model towards compact and businesslike models (2021, August 23) retrieved 23 August 2021 from https://techxplore.com/news/2021-08-edge-tunable-neural-network-framework.html
This papers is taxable to copyright. Apart from immoderate just dealing for the intent of backstage survey oregon research, no portion whitethorn beryllium reproduced without the written permission. The contented is provided for accusation purposes only.







 English (US) ·
English (US) ·